
Work in progress. script available soon including gas bills.
Bordgais Energy Charts
Distributed FFMPEG using Google App Engine
I’ve developed a distributed ffmpeg google app engine solution.
The solution uses a combination of publish subscribe and redis queues for distributed communication.
https://github.com/dmzoneill/appengine-ffmpeg
Its composed of 2 services which scale horizontally (default and worker).
Coordinator (default service and human interface)
#!/usr/bin/python
from flask import Flask
import os
import sys
import glob
import string
import random
import redis
import logging
from gcloud import storage, pubsub
from google.cloud import logging
PROJECT_ID = 'transcode-159215'
TOPIC = 'projects/{}/topics/message'.format(PROJECT_ID)
logclient = logging.Client()
logger = logclient.logger( "ffmpeg-pool" )
app = Flask(__name__)
app.config[ "SECRET_KEY" ] = "test"
app.debug = True
def publish( msg ):
pubsub_client = pubsub.Client( PROJECT_ID )
topic = pubsub_client.topic( "ffmpeg-pool" )
if not topic.exists():
topic.create()
topic.publish( msg )
@app.route( "/readlog" )
def readLog():
msg = ""
try:
for entry in logger.list_entries():
msg = msg + entry.payload + "
"
logger.delete()
except:
msg = ""
return msg
@app.route( "/cleantopic" )
def cleanTopics():
client = pubsub.Client( PROJECT_ID )
topic = client.topic( "ffmpeg-pool" )
topic.delete()
topic.create()
return "Cleaned topic"
@app.route( "/split" )
def split():
publish( "split" )
return "File queued for spliting"
@app.route( "/transcode" )
def transcode():
publish( "transcode" )
return "Job queued for transcoding"
@app.route( "/combine" )
def combine():
publish( "combine" )
return "Job queued for combining"
@app.route( "/" )
def home():
return "/split | /transcode | /combine | /cleantopic | /readlog"
if __name__ == '__main__':
app.run(host='127.0.0.1', port=8080, debug=True)Worker
import os
from gcloud import storage, pubsub, logging
import sys
import socket
import time
import redis
import glob
from google.cloud import logging
logclient = logging.Client()
logger = logclient.logger( "ffmpeg-pool" )
PROJECT_ID = 'transcode-159215'
TOPIC = 'projects/{}/topics/message'.format(PROJECT_ID)
psclient = None
pstopic = None
pssub = None
class RedisQueue(object):
def __init__( self, name, namespace = 'queue' ):
self.__db = redis.Redis( host = "redis-11670.c10.us-east-1-4.ec2.cloud.redislabs.com", port=11670 )
self.key = '%s:%s' %(namespace, name)
def qsize( self ):
return self.__db.llen( self.key )
def empty( self ):
return self.qsize() == 0
def put( self, item ):
self.__db.rpush( self.key, item )
def get( self, block=True, timeout=None ):
if block:
item = self.__db.blpop( self.key, timeout=timeout )
else:
item = self.__db.lpop( self.key )
if item:
item = item[1]
return item
def get_nowait( self ):
return self.get( False )
def download( rfile ):
client = storage.Client( PROJECT_ID )
bucket = client.bucket( PROJECT_ID + ".appspot.com" )
blob = bucket.blob( rfile )
with open( "/tmp/" + rfile, 'w' ) as f:
blob.download_to_file( f )
logger.log_text( "Worker: Downloaded: /tmp/" + rfile )
def upload( rfile ):
client = storage.Client( PROJECT_ID )
bucket = client.bucket( PROJECT_ID + ".appspot.com" )
blob = bucket.blob( rfile )
blob = bucket.blob( rfile )
blob.upload_from_file( open( "/tmp/" + rfile ) )
logger.log_text( "Worker: Uploaded /tmp/" + rfile )
def transcode( rfile ):
download( rfile )
os.system( "rm /tmp/output*" )
ret = os.system( "ffmpeg -i /tmp/" + rfile + " -c:v libx265 -preset medium -crf 28 -c:a aac -b:a 128k -strict -2 /tmp/output-" + rfile + ".mkv" )
if ret:
logger.log_text( "Worker: convert failed : " + rfile + " - " + str( ret ).encode( 'utf-8' ) )
return
upload( "output-" + rfile + ".mkv" )
def split():
rqueue = RedisQueue( "test" )
download( "sample.mp4" )
os.system( "rm -f /tmp/chunk*" )
ret = os.system( "ffmpeg -i /tmp/sample.mp4 -map 0:a -map 0:v -codec copy -f segment -segment_time 10 -segment_format matroska -v error '/tmp/chunk-%03d.orig'" )
if ret:
return "Failed"
for rfile in glob.glob( "/tmp/chunk*" ):
basename = os.path.basename( rfile )
upload( basename )
rqueue.put( basename )
def combine():
client = storage.Client( PROJECT_ID )
bucket = client.bucket( PROJECT_ID + ".appspot.com" )
blobs = bucket.list_blobs()
os.system( "rm /tmp/*" )
names = []
for blob in blobs:
if "output" in blob.name:
names.append( blob.name.encode( 'utf-8' ) )
names.sort()
with open( '/tmp/combine.lst', 'w' ) as f1:
for name in names:
f1.write( "file '/tmp/" + name + "'\n" )
download( name )
logger.log_text( "Worker: created combine list: /tmp/combine.lst" )
ret = os.system( "ffmpeg -f concat -safe 0 -i /tmp/combine.lst -c copy /tmp/combined.mkv" )
if ret:
logger.log_text( "Worker: combine failed: /tmp/combine.mkv - " + str(ret).encode( 'utf-8' ) )
return
upload( "combined.mkv" )
def subscribe():
global psclient, pstopic, pssub
psclient = pubsub.Client( PROJECT_ID )
pstopic = psclient.topic( "ffmpeg-pool" )
if not pstopic.exists():
pstopic.create()
pssub = pstopic.subscription( "ffmpeg-worker-" + socket.gethostname() )
if not pssub.exists():
pssub.create()
def handlemessages():
global psclient, pstopic, pssub
rqueue = RedisQueue( 'test' )
subscribe()
while True:
messages = pssub.pull( return_immediately=False, max_messages=110 )
for ack_id, message in messages:
payload = message.data.encode( 'utf-8' ).replace( u"\u2018", "'" ).replace( u"\u2019", "'" )
logger.log_text( "Worker: Received message: " + payload )
try:
pssub.acknowledge( [ack_id] )
if payload == "combine":
combine()
elif payload == "split":
split()
else:
rfile = rqueue.get()
basename = os.path.basename( rfile )
logger.log_text( "Worker: Redis popped: " + basename )
while basename != "None":
transcode( basename )
rfile = rqueue.get()
basename = os.path.basename( rfile )
logger.log_text( "Worker: Redis popped: " + rfile )
except Exception as e:
logger.log_text( "Worker: Error: " + e.message )
sys.stderr.write( e.message )
subscribe()
time.sleep( 1 )
if __name__ == '__main__':
handlemessages()Android Digiweb App
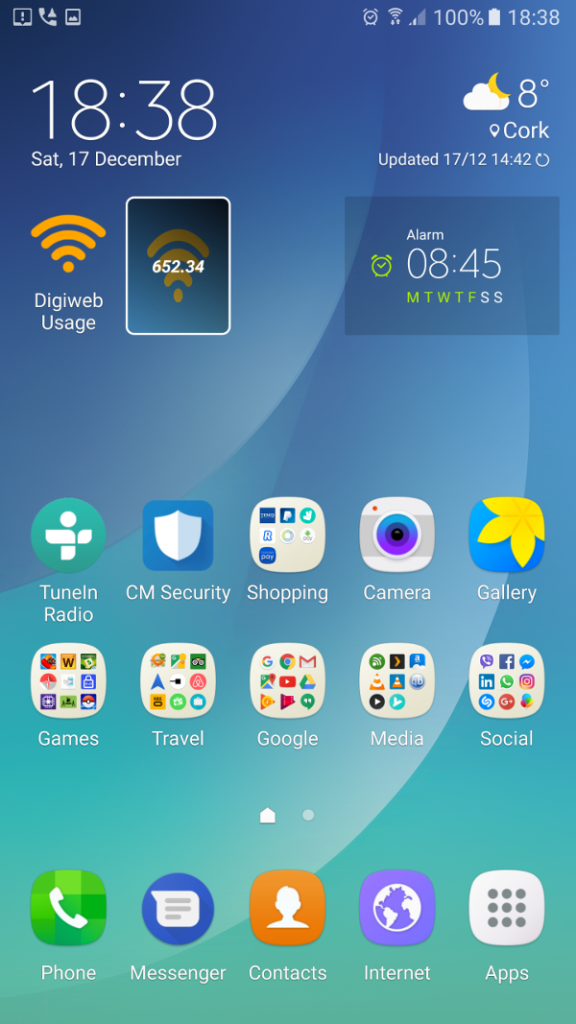
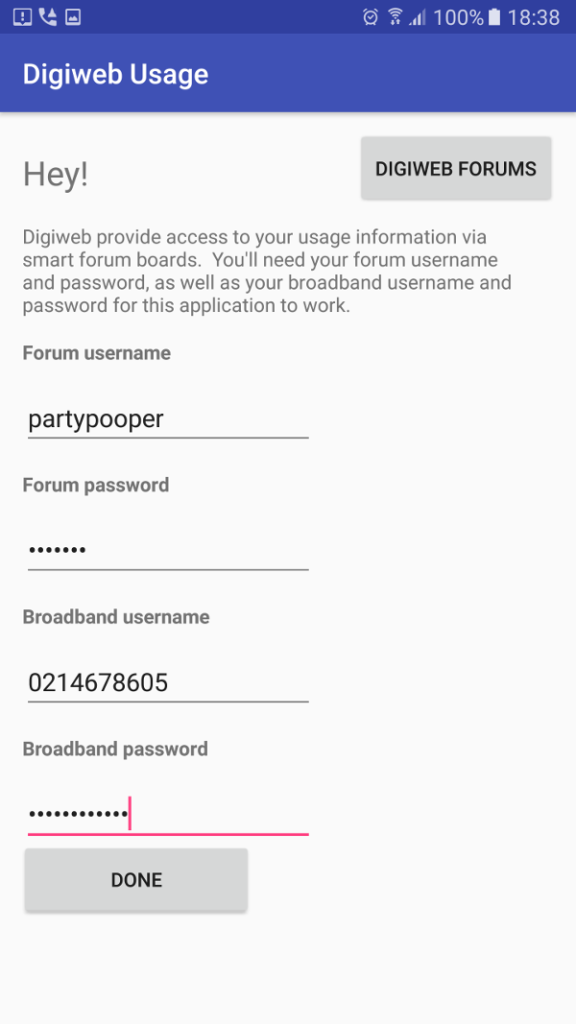
For the first time in 5 years i banged out an android app, and here it is Digiweb broadband usage indicator.
It fetches your broadband usage and displays it as a widget on home screen. Fairly basic, but does the job nicely.
https://play.google.com/store/apps/details?id=ie.fio.dave.digiwebusage&hl=en
 |  |
PyGTK Threaded Nautilus Filebot
As a heavy user of Nautilus and Filebot, i decided to integrate the two.
Following on from my previous article on column providers for nautilus, here as the additional functionality for nautilus filebot integration.
Its a basic threaded extension; for the most basic and most used operation, “Strict file renaming”.
It solves 95% of my usage scenarios. To find out how to use the code, see the article https://fio.ie/python-column-provider-nautilus/
Github: https://github.com/dmzoneill/filebot-nautilus
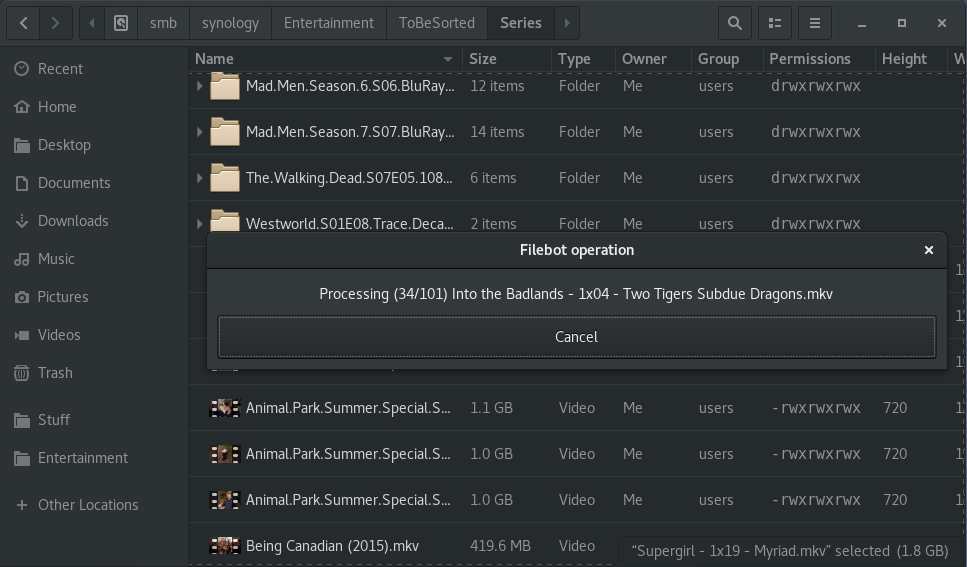
The code
#!/usr/bin/python
# dave@fio.ie
import os
import urllib
import logging
import re
import threading
import gi
gi.require_version('Nautilus', '3.0')
gi.require_version('Gtk', '3.0')
from gi.repository import Nautilus, GObject, Gtk, Gdk, GLib, GdkPixbuf
from hachoir_core.error import HachoirError
from hachoir_core.stream import InputIOStream
from hachoir_parser import guessParser
from hachoir_metadata import extractMetadata
from subprocess import Popen, PIPE
GObject.threads_init()
class VideoMetadataExtension(GObject.GObject, Nautilus.ColumnProvider, Nautilus.MenuProvider, Nautilus.InfoProvider):
def __init__(self):
logging.basicConfig(filename='/tmp/VideoMetadataExtension.log',level=logging.DEBUG)
self.videomimes = [
'video/x-msvideo',
'video/mpeg',
'video/x-ms-wmv',
'video/mp4',
'video/x-flv',
'video/x-matroska'
]
self.win = None
def get_columns(self):
return (
Nautilus.Column(name="NautilusPython::video_width_columnn",attribute="video_width",label="Width",description="Video width"),
Nautilus.Column(name="NautilusPython::video_height_columnn",attribute="video_height",label="Height",description="Video height"),
)
def update_file_info_full(self, provider, handle, closure, file_info):
filename = urllib.unquote(file_info.get_uri()[7:])
video_width = ''
video_height = ''
name_suggestion = ''
file_info.add_string_attribute('video_width', video_width)
file_info.add_string_attribute('video_height', video_height)
file_info.add_string_attribute('name_suggestion', name_suggestion)
if file_info.get_uri_scheme() != 'file':
logging.debug("Skipped: " + filename)
return Nautilus.OperationResult.COMPLETE
for mime in self.videomimes:
if file_info.is_mime_type(mime):
GObject.idle_add(self.get_video_metadata, provider, handle, closure, file_info)
logging.debug("in Progress: " + filename)
return Nautilus.OperationResult.IN_PROGRESS
logging.debug("Skipped: " + filename)
return Nautilus.OperationResult.COMPLETE
def get_file_items_full(self, provider, window, files):
for mime in self.videomimes:
for file in files:
if file.get_uri_scheme() == 'file' and file.is_mime_type(mime):
top_menuitem = Nautilus.MenuItem(name='NautilusPython::Filebot', label='Filebot', tip='Filebot renamer')
submenu = Nautilus.Menu()
top_menuitem.set_submenu(submenu)
filebot_tvdb_menuitem = Nautilus.MenuItem(name='NautilusPython::FilebotRenameTVDB', label='Filebot TVDB', tip='Fetch names from TVDB')
filebot_tvdb_menuitem.connect('activate', self.filebot_activate_cb, files, 'tvdb')
submenu.append_item(filebot_tvdb_menuitem)
filebot_moviedb_menuitem = Nautilus.MenuItem(name='NautilusPython::FilebotRenameMoviewDB', label='Filebot MovieDB', tip='Fetch names from MovieDB')
filebot_moviedb_menuitem.connect('activate', self.filebot_activate_cb, files, 'moviedb')
submenu.append_item(filebot_moviedb_menuitem)
return top_menuitem,
def filebot_activate_cb(self, menu, files, source):
self.win = FileBotWindow(self, source, files)
self.win.connect("delete-event", Gtk.main_quit)
self.win.show_all()
Gtk.main()
def get_video_metadata(self, provider, handle, closure, file_info):
video_width = ''
video_height = ''
name_suggestion = ''
filename = urllib.unquote(file_info.get_uri()[7:])
filelike = open(filename, "rw+")
try:
filelike.seek(0)
except (AttributeError, IOError):
logging.debug("Unabled to read: " + filename)
Nautilus.info_provider_update_complete_invoke(closure, provider, handle, Nautilus.OperationResult.FAILED)
return False
stream = InputIOStream(filelike, None, tags=[])
parser = guessParser(stream)
if not parser:
logging.debug("Unabled to determine parser: " + filename)
Nautilus.info_provider_update_complete_invoke(closure, provider, handle, Nautilus.OperationResult.FAILED)
return False
try:
metadata = extractMetadata(parser)
except HachoirError:
logging.debug("Unabled to extract metadata: " + filename)
Nautilus.info_provider_update_complete_invoke(closure, provider, handle, Nautilus.OperationResult.FAILED)
return False
if metadata is None:
logging.debug("Metadata None: " + filename)
Nautilus.info_provider_update_complete_invoke(closure, provider, handle, Nautilus.OperationResult.FAILED)
return False
matchObj = re.search( r'Image width: (.*?) pixels', str(metadata), re.M|re.I)
if matchObj:
video_width = matchObj.group(1)
matchObj = re.search( r'Image height: (.*?) pixels', str(metadata), re.M|re.I)
if matchObj:
video_height = matchObj.group(1)
file_info.add_string_attribute('video_width', video_width)
file_info.add_string_attribute('video_height', video_height)
file_info.add_string_attribute('name_suggestion', name_suggestion)
logging.debug("Completed: " + filename)
file_info.invalidate_extension_info()
Nautilus.info_provider_update_complete_invoke(closure, provider, handle, Nautilus.OperationResult.COMPLETE)
return False
class FileBotWindow(Gtk.Window):
def __init__(self, videoMetadataExtension, source, files):
self.todo = len(files)
self.processing = 0
self.files = files
self.source = source
self.quit = False
self.videoMetadataExtension = videoMetadataExtension
Gtk.Window.__init__(self, title="Filebot operation")
self.set_size_request(200, 100)
self.set_border_width(10)
self.set_type_hint(Gdk.WindowTypeHint.DIALOG)
vbox = Gtk.Box(orientation=Gtk.Orientation.VERTICAL, spacing=6)
self.add(vbox)
self.working_label = Gtk.Label(label="Working")
vbox.pack_start(self.working_label, True, True, 0)
self.button = Gtk.Button(label="Cancel")
self.button.connect("clicked", self.on_button_clicked)
vbox.pack_start(self.button, True, True, 0)
#GObject.timeout_add_seconds(1, self.process, files, source)
self.update = threading.Thread(target=self.process)
self.update.setDaemon(True)
self.update.start()
def process(self):
for file in self.files:
if file.get_uri_scheme() != 'file':
continue
filename = urllib.unquote(file.get_uri()[7:])
self.filebot_process(filename)
def on_button_clicked(self, widget):
self.quit = True
self.close()
def filebot_process(self, filename):
if self.quit == True:
return
self.processing = self.processing + 1
text = "Processing (" + str(self.processing) + "/" + str(self.todo) + ") " + os.path.basename(filename)
GObject.idle_add( self.working_label.set_text, text, priority=GObject.PRIORITY_DEFAULT )
p = Popen(['filebot', '-rename', filename,'--db', self.source], stdin=PIPE, stdout=PIPE, stderr=PIPE)
output, err = p.communicate(b"input data that is passed to subprocess' stdin")
rc = p.returncode
if self.processing == self.todo:
GObject.idle_add( self.close, priority=GObject.PRIORITY_DEFAULT )Python column provider for Gnome Files (Nautilus)
Below is an example of a python column provider for nautilus.
Identifying poor quality video files 480p, 720p … is difficult in nautilus at a glance.
You need to open the file properties to view the video metadata.
While there are a number of extensions out there for EXIF etc, i decided to implement my own.
Originally i tried to use MediaInfo, but it was far too slow. This is what i ended up with.
To activate it, just login and logout, or kill nautilus and restart it.
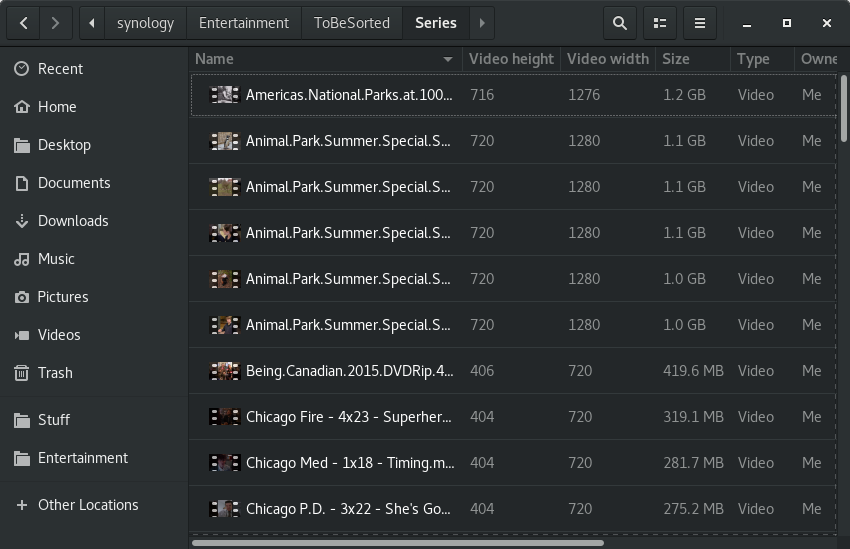
Create target directory and file
mkdir -vp ~/.local/share/nautilus-python/extensions
touch ~/.local/share/nautilus-python/extensions/VideoMetaData.pyInstall python libraries
pip install hachoir-metadata
pip install hachoir-parser
pip install hachoir-coreAdd this to ~/.local/share/nautilus-python/extensions/VideoMetaData.py
#!/usr/bin/python
# dave@fio.ie
import os
import urllib
import logging
import re
import gi
gi.require_version('Nautilus', '3.0')
gi.require_version('Gtk', '3.0')
from gi.repository import Nautilus, GObject, Gtk, Gdk, GdkPixbuf
from hachoir_core.error import HachoirError
from hachoir_core.stream import InputIOStream
from hachoir_parser import guessParser
from hachoir_metadata import extractMetadata
class VideoMetadataExtension(GObject.GObject, Nautilus.ColumnProvider, Nautilus.MenuProvider, Nautilus.InfoProvider):
def __init__(self):
logging.basicConfig(filename='/tmp/VideoMetadataExtension.log',level=logging.DEBUG)
pass
def get_columns(self):
return (
Nautilus.Column(name="NautilusPython::video_width_columnn",attribute="video_width",label="Width",description="Video width"),
Nautilus.Column(name="NautilusPython::video_height_columnn",attribute="video_height",label="Height",description="Video height"),
)
def update_file_info_full(self, provider, handle, closure, file_info):
filename = urllib.unquote(file_info.get_uri()[7:])
video_width = ''
video_height = ''
name_suggestion = ''
file_info.add_string_attribute('video_width', video_width)
file_info.add_string_attribute('video_height', video_height)
file_info.add_string_attribute('name_suggestion', name_suggestion)
if file_info.get_uri_scheme() != 'file':
logging.debug("Skipped: " + filename)
return Nautilus.OperationResult.COMPLETE
videomimes = [
'video/x-msvideo',
'video/mpeg',
'video/x-ms-wmv',
'video/mp4',
'video/x-flv',
'video/x-matroska'
]
for mime in videomimes:
if file_info.is_mime_type(mime):
GObject.idle_add(self.get_video_metadata, provider, handle, closure, file_info)
logging.debug("in Progress: " + filename)
return Nautilus.OperationResult.IN_PROGRESS
logging.debug("Skipped: " + filename)
return Nautilus.OperationResult.COMPLETE
def get_video_metadata(self, provider, handle, closure, file_info):
video_width = ''
video_height = ''
name_suggestion = ''
filename = urllib.unquote(file_info.get_uri()[7:])
filelike = open(filename, "rw+")
try:
filelike.seek(0)
except (AttributeError, IOError):
logging.debug("Unabled to read: " + filename)
Nautilus.info_provider_update_complete_invoke(closure, provider, handle, Nautilus.OperationResult.FAILED)
return False
stream = InputIOStream(filelike, None, tags=[])
parser = guessParser(stream)
if not parser:
logging.debug("Unabled to determine parser: " + filename)
Nautilus.info_provider_update_complete_invoke(closure, provider, handle, Nautilus.OperationResult.FAILED)
return False
try:
metadata = extractMetadata(parser)
except HachoirError:
logging.debug("Unabled to extract metadata: " + filename)
Nautilus.info_provider_update_complete_invoke(closure, provider, handle, Nautilus.OperationResult.FAILED)
return False
if metadata is None:
logging.debug("Metadata None: " + filename)
Nautilus.info_provider_update_complete_invoke(closure, provider, handle, Nautilus.OperationResult.FAILED)
return False
matchObj = re.search( r'Image width: (.*?) pixels', str(metadata), re.M|re.I)
if matchObj:
video_width = matchObj.group(1)
matchObj = re.search( r'Image height: (.*?) pixels', str(metadata), re.M|re.I)
if matchObj:
video_height = matchObj.group(1)
file_info.add_string_attribute('video_width', video_width)
file_info.add_string_attribute('video_height', video_height)
file_info.add_string_attribute('name_suggestion', name_suggestion)
logging.debug("Completed: " + filename)
file_info.invalidate_extension_info()
Nautilus.info_provider_update_complete_invoke(closure, provider, handle, Nautilus.OperationResult.COMPLETE)
return False